This week's going to be all about optimization.
I've been trying to find the best balance between effort put in and performance increase as far as acceleration structures go. I thought about a kd-tree for a while, but the problem with those is the difficulty I've had finding a simple-to-implement sorting algorithm. I'm using a parallel selection sort based on
Eric Bainville's work since it was extremely basic. It's not fast, but I don't really care about speed of sort for photon mapping itself because it's all done before-hand. The problem is that kd-trees require continuous refinement and re-sorting as you construct them. Every time you go down a level you swap the axis you're splitting on and that requires a partial re-sort. For the time being, I've passed on kd-trees because of these issues. Instead, I've implemented a spatial grid that just works by partitioning 3D-space uniformly. It appears to be working so far, I've got a pretty decent speed-up, but it's also slightly broken at the moment:
It's not actually broken though, it's behaving exactly as I wanted it to...it just isn't complete.Right now I'm only looking for photons within the grid cell where the ray tracing step intersected the object. This is partially correct, but I really need to be gathering photons from neighboring cells in all 3 dimensions. The distance away from which I should be checking other cells is equivalent to the radius of the photons that I'm emitting. That's next!
Update: 4/15/2012
Tried implementing neighbor search with my uniform grid...now I see why people don't roll their own algorithms! Performance was actually worse than without any "acceleration" structure at all, and I didn't have control over the span that I was searching over easily. One of the biggest problems I'm looking at right now is varying the size of the cells based on the radius of the photons within the scene. This isn't difficult itself, but then adjusting at run-time the resolution of the grid itself IS difficult to wrap my head around right now. I'll need to think on this for a while. If I can enforce that grid cells are the same dimensions as the radius of the photons, the nearest neighbor search becomes a problem with at most 26 grid cells involved. Ultimately, the kd-tree is looking like a better solution still, even if I have no idea how to do it yet.
Also, I've come to realize that my approach thus far is strikingly similar to that of
Martin Fleisz.
Update 4/16/2012
Well I followed my hunch and looked into how Martin Fleisz approached acceleration structures. I'm not quite done with my own spin on his algorithm, but I'm getting close and thought I should update to say that hopefully this should be the one I settle on. Initial performance seems promising....if it's true. Hard to tell if I'm getting all the photons I should be with my queries. In the meantime, here's an awesome (broken) screenshot of the current state of the app:
Update: 4/16/2012
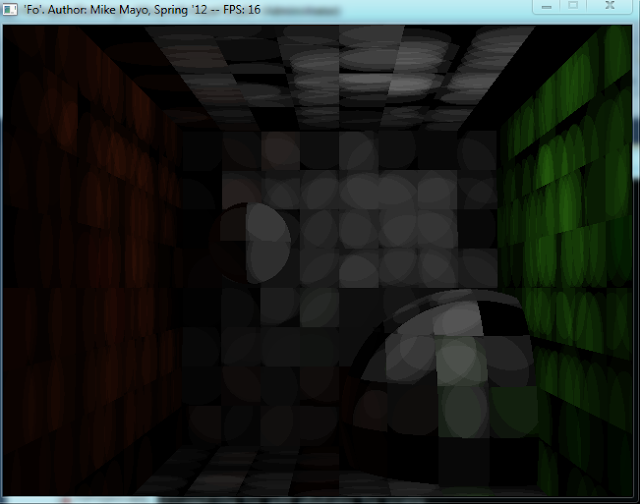
Well I fixed that bug, and after a night of hacking away at one problem after another I've come to this point:
I really don't know how I feel about this. It's hard to see but the final gather is still broken and cuts apart some photons, the map doesn't quite look accurate anymore as far as the inter-reflections on the larger sphere from the wall, and the grid structure itself is producing SERIOUS aliasing obviously.
I'm really worried about the aliasing with this approach. I think the only way I can get rid of it is to cast multiple rays per pixel and then average the results. This would effectively cut my performance to a quarter of what it is now if I want it done right, effectively negating the entire advantage of this approach...
I guess I'll see what I think of it tomorrow...
Update: 4/17/2012
Here's an example of what I think is causing the aliasing. It's a closeup of the photons being cut off at grid boundaries like they shouldn't be:
Update: 4/18/2012
Fixed the error on the left and right walls, introduced a new one I can't figure out on literally every other flat surface and portions of the spheres. You can see it in this shot that also shows some really AWESOME errors I caused on purpose playing with the floating-point error:
Update: 4/19/2012
Still broken =/
Update: 4/21/2012
I FINALLY fixed that bug. It turned out to be a typo in my manual magnitude calculation for a certain vector. I hate myself for it...
I'm experimenting at the moment with larger batches of photons, and more uniform distributions. I'd expect that to be the highlight of next week's content and progress. Looking forward even more, I hope to play with texture memory a bit for Week 8!
Update: 4/21/2012
It's amazing what a better random function can do :)













